
新一轮科技革命已然开启,5G、大数据中心、人工智能等领域发展如火如荼。而随着这些新型科技在各行业内应用普及,数据量级递增,其价值也越来越受到全社会重视。
近年来,重大数据泄漏事件频发,对数据安全领域从业者是机遇更是挑战。创新技术的应用和发展,为数据安全产业提供新的发展力,如AI在数据防泄漏中的应用。
那么,现行的数据防泄漏架构是怎样的?AI应用下产生的知识图谱又是怎么一回事?让我们跟着明朝万达的数据安全专家一同来探讨一二。
数据防泄漏问题
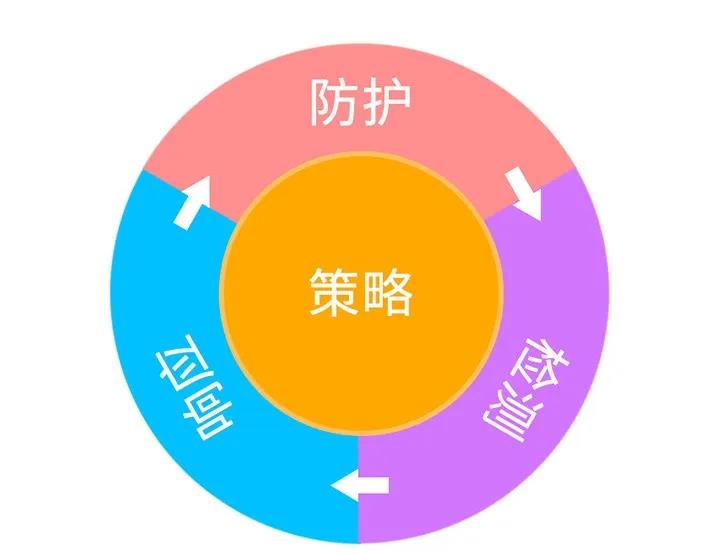
明朝万达现有数据防泄漏架构主要基于PPDR模型来实现,PPDR由策略、防护、检测、响应四部分机制组成。
其中,策略是核心,描述系统哪些资源需要保护;防护是加密机制等技术;响应是应急策略;检测是入侵检测、数据防泄漏等技术。
数据防泄漏其核心能力就是内容识别,识别出要保护的数据对象,然后对数据进行分类分级,最后根据客户需求设置相应等级响应策略完成相应的数据防泄漏防护策略,从而达到保护系统安全和数据防泄漏的目的。
PPDR模型示意图
-----
数据内容识别技术发展
明朝万达数据安全专家表示,当下数据内容识别技术的发展已经到了第三代。在数据内容识别技术发展过程中:
第一代是基于规则匹配方法实现,进而对识别内容进行分类分级策略,该方法不具备智能性,无法做到准确分类分级,且局限性很大,不利于扩展到其他行业。
第二代识别技术是基于机器学习方法去实现,该方法已具备初步的智能性,基于机器学习方法时,需要人工进行标注数据,而后构建复杂的特征对文本内容进行分类,此方法已具备初步智能,但是需要耗费大量人力物力来进行数据标注和特征构建。
第三代数据识别技术是基于知识图谱来实现,基于知识图谱技术能利用正向反馈机制和自我学习两种方式减少人工标注量,减少专家先验知识和避免知识片面性,基于远程监督学习达到数据自动分类分级的目的,构建出行业知识体系和领域内知识图谱,继而扩展到其他行业领域。

数据识别技术发展历程时间轴
-----
知识图谱简介
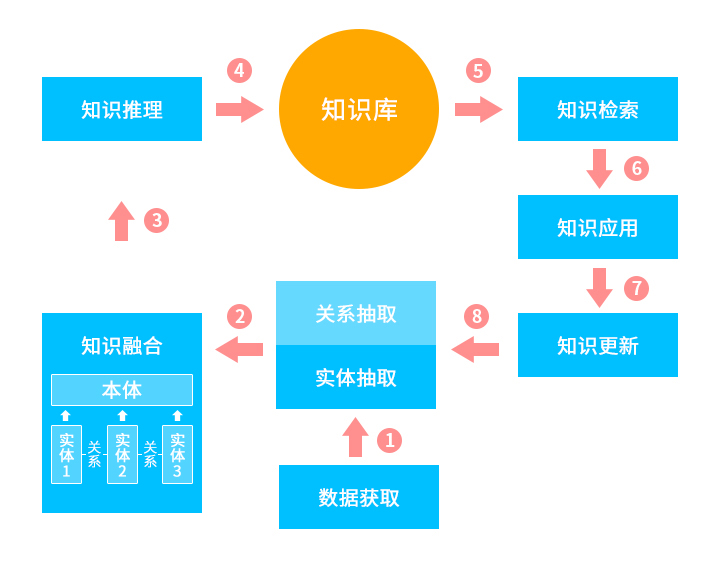
知识图谱的架构包括自身的逻辑结构以及构建知识图谱所采用的技术结构。
逻辑结构分为数据层和模式层两个层次,数据层由各个节点和边组成,节点表示“实体”,边表示实体间的“关系”,然后基于实体与关系经过知识融合得到某一类的数据本体。模式层在数据层之上,是知识图谱的核心,由数据层经过提炼抽象得到。
明朝万达数据安全专家解释:知识图谱由这两部分结构提供从“关系”的角度去分析问题的能力,利用模式层预测能力去分析问题,在分析问题的过程中可以根据分析的结果,反馈到数据层,利用正向反馈过程中的先验知识在数据层加入正反向样本使模型更加智能化,从而达到不断自我学习目的,在完善与构建知识图谱的过程中通过不断增加正反样本来逐步减少人为的干预,使知识图谱更加完善,最后构建出领域内知识。
知识图谱构建与应用流程图
-----
知识图谱简介
基于知识图谱的文本分类结构图
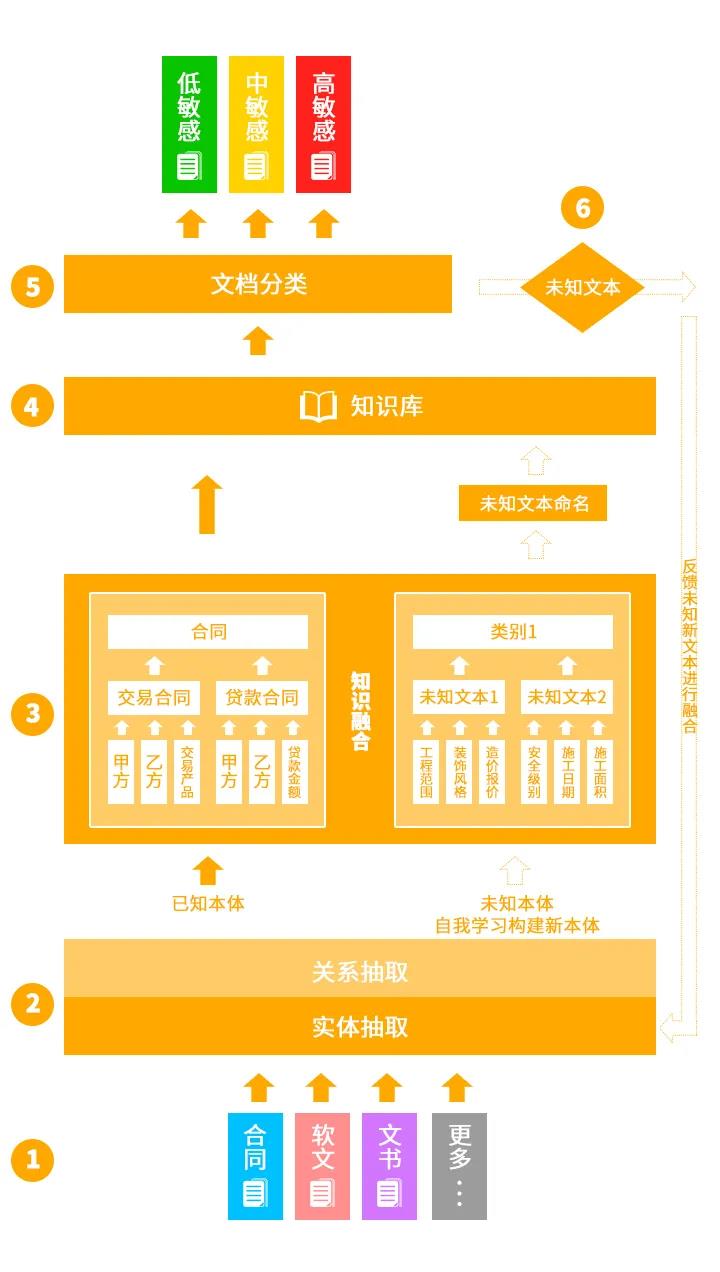
实施步骤:
本实例基于已知标签文本的合同等类别和未知标签文本的数据进行分类来对知识图谱进行实施运用,大致分为数据输入,实体关系等属性抽取,知识融合和数据分类,然后对未知的文本进行正向反馈和自我学习,达到识别敏感数据分类分级的目的。

-----
意义与展望
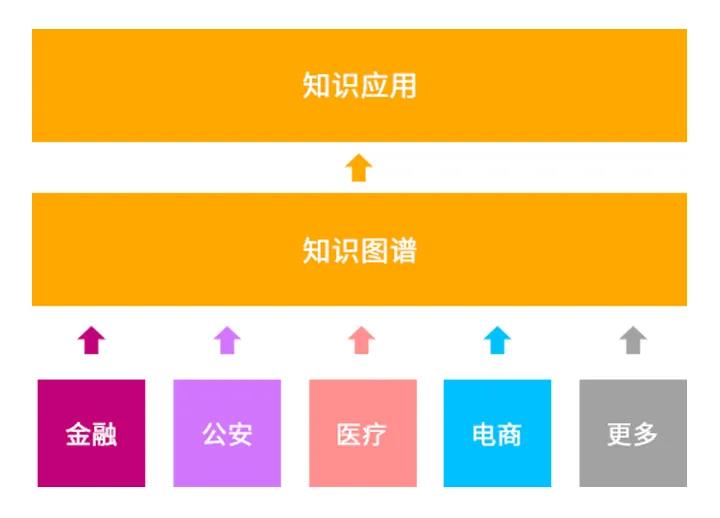
知识图谱作为人工智能的支撑基础,是人工智能的必经之路,企业在发展技术的同时更应重视领域+知识图谱发展。
在未来,技术不是公司的核心竞争力,多年积累的行业领域数据才是壁垒,要形成数据养育知识,知识反哺数据,领域数据和知识图谱应相辅相成,共同发展。知识图谱因其能不断自我学习和具备正向反馈机制可以很好迁移到其他领域。
知识图谱扩展领域应用示意图


